Jeżeli przeprowadzasz analizę, zawsze uzyskasz jakiś rezultat w postaci wartości, wykresów, procentów. Jednak gdy robisz to źle (na przykład porównujesz nieodpowiednie metryki lub korzystasz z niepełnych danych) wyniki będą błędne, mimo, że poparte liczbami. Jeżeli zbierasz złe dane, dokonujesz złych analiz – wyciągasz złe wnioski i stawiasz złe rekomendacje. Czyli? Marnujesz siły i zasoby na bezsensowny proces.
O sensie całego procesu analizy danych decyduje zbieranie poprawnych danych i wyciąganie poprawnych wniosków. Poprawnych? Prawdziwych (odpowiadających rzeczywistości) i użytecznych (odpowiadających kluczowym dla nas metrykom).
I chociaż w teorii brzmi to banalnie – w praktyce zweryfikowanie poprawności analizy jest jednym z trudniejszych elementów całego procesu. Jest kilka metod, aby to zrobić.
Dzisiaj proponujemy pracę u podstaw: czyli unikanie 8 głównych błędów popełnianych w analityce internetowej.
Na co powinieneś uważać podczas przeprowadzania analiz danych w analityce internetowej?
Jeżeli analizujesz długookresowy trend, powinieneś zawsze zwracać uwagę na zewnętrzne czynniki, które mogą wpłynąć na krzywą na wykresie.
Wyobraź sobie, że obserwujesz zachowanie sprzedaży w czasie (powiedzmy, roku). Zauważasz, że od maja do lipca sprzedaż w Twoim sklepie internetowym wzrasta. Jeszcze zanim otworzysz szampana, świętując z całym zespołem świetny wynik – zastanów się, czy aby optymalizacja serwisu jest jedyną przyczyną wzrostu sprzedaży. Czy na pewno dział marketingu nie przeprowadził w tym czasie kampanii reklamowej, co wpłynęło na poprawienie wyników sprzedaży? A może ceny produktów zostały znacząco obniżone w stosunku do konkurencji?
Gdy porównujemy metryki w czasie, może zdarzyć się, że nie bierzemy pod uwagę pełnego obrazu sytuacji: nic nie dzieje się w próżni, dlatego zanim przypiszemy efekt konkretnej akcji z naszej strony, trzeba wykluczyć inne czynniki, które mogą mieć wpływ na dany wynik. Albo przynajmniej – zdać sobie z nich sprawę.
Podobnie jak w pierwszym punkcie: podczas analizy ważne jest szerokie spojrzenie uwzględniające różne czynniki, które determinują określony wynik. Sezonowość wydaje się być oczywistym elementem analizy: przecież każdy wie, że ludzie chętniej kupują lody w lecie niż zimie, a bombki świąteczne zapewne lepiej sprzedają się w grudniu niż w styczniu. Jednak przy analizie współczynnika optymalizacji konwersji warto głębiej przekopać się przez zagadnienie sezonowości.
Załóżmy, że w e-sklepie ze sprzętem narciarskim zauważamy wyraźne zwiększenie ruchu we wrześniu, jednak sprzedaż uparcie stoi w miejscu. Tym samym obserwujemy spadek współczynnika konwersji: użytkownicy wchodzą do naszego serwisu ale nie dokonują zakupu. Czy jest to dowód, że nasza strona działa źle i należy szybko przeprowadzić jakieś zmiany? Niekoniecznie.
Jesień to sezon, w którym ludzie przygotowują się do wyjazdów narciarskich. Jeżeli weźmiemy to pod uwagę zrozumiemy, że prawdopodobnie wiele z naszych użytkowników zaczyna „rozglądać” się za sprzętem. Zapewne planują zrobić zakupy, jednak właśnie w tym okresie potrzebują jeszcze czasu na podjęcie ostatecznej decyzji. Wówczas zamiast na gwałt rozpoczynać testy koloru przycisku „call to action” warto zwrócić uwagę na wyraźne podkreślenie USP naszej oferty czy zapewnienie odpowiedniej ilości informacji i rekomendacji. Na tym etapie powinniśmy także poprawnie skonfigurować kampanie remarketingową oraz zadbać o to, aby odwiedzający zapisali się do newslettera (jeżeli przyjdzie sezon zakupów, możemy im o sobie przypomnieć). Albo – możemy wykorzystać bodźce skłaniające do szybszego podjęcia decyzji o zakupie.
Jeżeli ja mam 2 nogi, a mój pies ma 4 to średnio mamy po 3 nogi. Bezsensu? No właśnie. Większość ludzi wie, że w wielu przypadkach wyliczanie średniej arytmetycznej jest zupełnie nieadekwatne, a jednak często korzysta z niej w swoich analizach. Zazwyczaj taka informacja nie daje żadnego obrazu i nie można na jej podstawie wyciągać rzetelnych wniosków.
W Google Analytics znajdziemy sporo danych na temat średnich wartości poszczególnych metryk. Na przykład średniego czasu przebywania na stronie. Ta średnia, sama w sobie w sobie, jest bezwartościowa: mamy użytkowników, którzy na stronie spędzają 45 min, inni 2 sekundy. Jeżeli średni czas wynosi 2:53, nie daje nam to żadnej konkretnej informacji: nie wiemy ilu użytkowników było na stronie faktycznie 2:53 minuty, ilu 45 minut a ilu 2 sekundy. Wobec tego każda akcja podjęta na podstawie takich danych jest z góry nieefektywna.
Pojawia się pytanie: w takim razie po co Google Analytics podaje mi te średnie? Sprawdzają się one przy segmentacji: dzięki średnim wartościom możemy zawęzić zbiór i analizować wymierne dane.
Gdy stworzymy segment użytkowników, którzy korzystają z różnych przeglądarek, a następnie dodamy do tego średni czas na stronie, możemy zauważyć, że w przypadku przeglądarki Internet Explorer wartość ta jest dużo niższa niż przy innych przeglądarkach. To sensowny wniosek: być może nasza strona źle działa w danej przeglądarce – ładuje się zbyt wolno lub poszczególne elementy serwisu nie są odpowiednio wyświetlane?
Sam współczynnik, chociaż nie umniejszamy jego istoty w analizie danych (przecież wiecie, że uwielbiamy współczynnik konwersji) nie zawsze jest odzwierciedleniem rzeczywistości. Dlaczego jest to poważny błąd w analityce internetowej? Może zdarzyć się tak, że wpadniemy w zachwyt widząc w naszym Google Analytics współczynnik konwersji na poziomie 20%. Jednak, gdy zwrócimy uwagę na wartości nominalne zauważymy, że tego dnia w serwisie było 10 osób, z czego 2 kupiły produkty. Nasz współczynnik konwersji wyniósł 20%, ale czy taka wartość odpowiada rzeczywistości, czy to czysty przypadek?
Porównywanie samych współczynników może prowadzić do błędnych wniosków: przy 200 konwersjach i 3000 wizyt otrzymujemy taki sam współczynnik konwersji co przy 2 konwersjach i 30 wizytach. Ważne, aby zawsze zwrócić uwagę na dane nominalne: w przypadku współczynnika konwersji musimy zebrać odpowiedni ruch na stronie i odpowiednią liczbę konwersji aby osiągnąć wyniki, które odzwierciedlają rzeczywistość. W takim razie co zrobić w przypadku, gdy nasz serwis generuje zbyt mało ruchu? Zastosować pewien agregat czasu, w którym uda nam się wygenerować odpowiednią próbę – na przykład tydzień. Wówczas, zamiast dzień pod dniu patrzeć na współczynnik konwersji, porównujemy go w okresach tygodniowych.
W analizie danych płynących z testów A/B istotność statystyczna określa, czy różnice w wyniku są konsekwencją przypadku czy zmian, których dokonaliśmy. Powiedzmy, że porównujemy wersję trzech i czterech kroków w koszyku. Gdy wygrała wersja trzech kroków, możemy pomyśleć, że jest to po prostu zmiana, dzięki której więcej użytkowników konwertuje. Ale równie dobrze może być to przypadek: wersja ta wyświetliła się akurat osobom, które chciały dokonać zakupu w naszym serwisie w danym czasie, podczas gdy na wersję z czterema krokami trafili użytkownicy, którzy nie mieli zamiaru nic u nas kupić i przypadkowo dostali się do koszyka. Jak to zweryfikować?
Z pomocą przychodzi właśnie poziom istotności statystycznej. Warto odwołać się do niej na każdym etapie analiz w analityce internetowej w naszym serwisie: na etapie planowania (aby wiedzieć ile powinien trwać test) oraz oceny wyników (aby mieć pewność, że rezultat jest istotny statycznie – czyli osiągnął poziom ufności równy bądź większy niż 95%).
W sukurs przychodzą dwa proste narzędzia (możemy je znaleźć na Visual Website Optimizer):
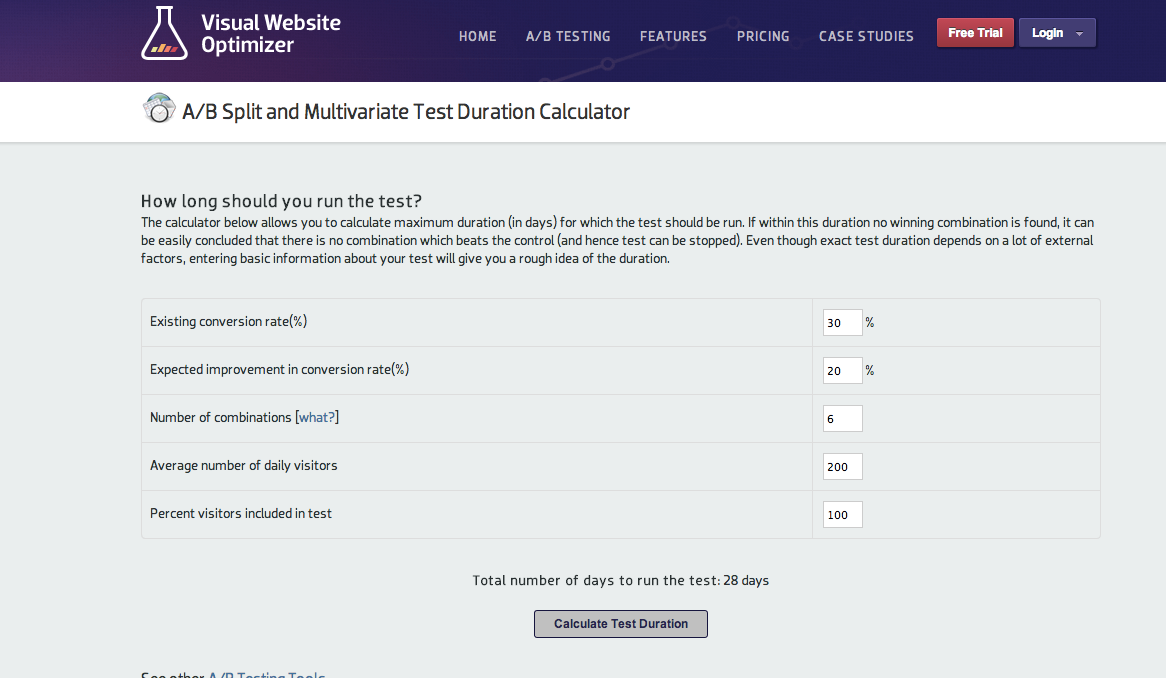
Dzięki kalkulatorowi długości trwania testu możemy dowiedzieć się, jak długo powinniśmy przeprowadzać konkretny test, aby wyniki były istotne statystycznie. To bardzo przydatne narzędzie podczas planowania. Na podstawie zmiennych takich jak aktualny współczynnik konwersji, oczekiwany współczynnik konwersji, liczba kombinacji, średnia liczba użytkowników dziennie oraz procent użytkowników, których zaangażujemy do testu, kalkulator wylicza nam liczbę dni potrzebnych do uzyskania wyników odzwierciedlających rzeczywistość. Jak na liczbę dni przekładają się te zmienne? W skrócie: im większy oczekiwany wzrost, im większa liczba użytkowników dziennie, im większy procent testowanych użytkowników naszej witryny – tym krótszy czas testu.

Ten kalkulator pozwoli ocenić, czy wynik testu jest istotny statystycznie. Po każdym teście powinniśmy to sprawdzić i zdecydować, czy test może się już zakończyć lub czy powinien trwać jeszcze dłużej. W tym kalkulatorze zmiennymi są: rzeczywista liczba użytkowników i rzeczywista liczba konwersji. Otrzymujemy prosty komunikat: test albo jest istotny, albo nie.
Pojawia się pytanie: co zrobić, gdy przy moim ruchu test osiągnie istotność statystyczną za 1892 dni? Możesz czekać 5 lat na wyniki, albo – co bardziej realne – zwiększyć ruch na stronie. Jednak do tego czasu spróbuj skorzystać z heurystyk, czyli zbioru hipotez, których nie trzeba już udowadniać (do heurystyk wykorzystywanych w optymalizacji współczynnika konwersji może należeć na przykład zasada zachowania spójności pomiędzy poszczególnymi stronami serwisu).
Częstym błędem podczas analizy danych jakościowych jest zły dobór próby oraz nieuzasadnione przenoszenie wyników na wszystkich użytkowników. Tutaj znowu w grę wchodzi odpowiedni agregat: tylko w przypadku dużego ruchu i dużej liczby odpowiedzi na ankietę możemy wyciągać wnioski na temat całej populacji.

Na naszym blogu prowadzimy prostą ankietkę: „o czym powinniśmy napisać”? Załóżmy, że na 10 udzielonych odpowiedzi, 4 brzmią: chcę przeczytać o historii założycieli największych sklepów internetowych na świecie. Czy to znaczy, że 40% naszych użytkowników jest zainteresowanych tym tematem? Nie, ponieważ w tym czasie na stronie było 1000 unikalnych użytkowników, z czego 990 w ogóle nie wypełniło ankiety (abstrahując od tego, czy już ją wypełniliście?).
Oczywiście informacje zebrane na podstawie ankiet są bardzo przydatne podczas optymalizacji konwersji nawet małych serwisów: gdy nie mamy jednak odpowiedniej próby, warto podchodzić do nich z rezerwą: traktować jako wskazówki, a nie wytyczne dotyczące zachowania każdego użytkownika.
Avinash Kaushik, powtarza: „twórz segmenty albo giń!” (do segmentation or die). Nie moglibyśmy się z tym bardziej zgodzić. Niestosowanie segmentacji jest poważnym, jeżeli nie dyskwalifikującym, błędem prowadzenia jakichkolwiek analiz w internecie.
Podobnie jak w przypadku orientowania się wyłącznie na średnią, analiza danych bez segmentów jest w najlepszym wypadku nieskuteczna. Clue analiz leży w „kopaniu” w danych i wyciąganiu z nich wniosków, które przyczynią się do wydawania konkretnych rekomendacji. Bez segmentacji patrzymy na metryki powierzchownie i tym samym wiele istotnych rzeczy po prostu nam ucieka.
Załóżmy: widzisz, że ilość przejść z karty produktu do koszyka na Twojej stronie gwałtownie spada. Co możesz zrobić z tą informacją? Niewiele. Jeżeli jednak przekopiesz te dane i wyodrębnisz segmenty – na przykład w oparciu o dane demograficzne – możesz odkryć, że dla poszczególnych grup użytkowników wyniki nie są takie same. Powiedzmy, że spadek obserwowany jest tylko w grupie 50+, podczas gdy w innych segmentach pozostaje bez zmian. Co to znaczy? Być może przycisk przejścia do koszyka nie jest czytelny dla starszych osób? Być może stosujesz za małą czcionkę?
Inna sytuacja: współczynnik konwersji rośnie jak szalony. Gdy jednak zakładasz segmenty zauważasz, że faktycznie rośnie w segmencie użytkowników komputerów, jednak w przypadku ruchu mobilnego (który jest pozornie niewidoczny, gdyż stanowi jedynie 2% ruchu w Twoim serwisie) gwałtownie spada. Dzięki zastosowaniu segmentów, zamiast pławić się w sukcesie, wiesz, gdzie podjąć kolejne akcje aby zwiększyć zyski dla Twojej firmy.
W tym samym czasie obserwujemy dwie rzeczy. Jako, że większość z nas lubi ciągi przyczynowo-skutkowe, mamy tendencje do łączenia ich ze sobą. Tymczasem opcji jest więcej: jedna rzecz może wynikać z drugiej, druga z pierwszej, obie mogą wynikać z trzeciej, albo mogą w ogóle nie mieć związku. Często niepotrzebnie marnujemy energię na szukanie powiązania między dwoma czynnikami, które czasami po prostu nie istnieje.
Są tacy, którzy głoszą, że spadek liczby piratów jest spowodowany przez globalne ocieplenie 🙂 Co więcej – badania to potwierdzają: wraz z wzrostem temperatury globu maleje liczba piratów. Piszą o tym nawet w Forbsie!

Więcej przykładów? Zobaczcie wykres zależności pomiędzy morderstwami w Stanach Zjednoczonych a udziałach w rynku przeglądarki Internet Explorer.
Źródło: http://wp-abtesting.com/correlation-vs-causality-and-why-this-matters-in-conversion-optimization/
Podobnie jak w wymienionych przypadkach, chyba nie muszę Was przekonywać, że fakt zakupu czerwonych sof do Waszego biura nie wpływa na wzrost współczynnika konwersji, mimo, że zadziało się to w tym samym czasie.
I chociaż podane przykłady są banalne i oczywiste, uznawanie korelacji za przyczynowość to jeden z poważnych błędów analityki internetowej, który popełnia się w analizach danych.
Dowód: powiedzmy, że testujesz dwie zmienne: nagłówek oraz kolor call-to-action. Wybierasz pomiędzy żółtym i czerwonym call-to-action, oraz pomiędzy nagłówkiem „8 na 10 osób poleca nasze produkty” i „80% osób poleca nasze produkty”

Największy wzrost współczynnika konwersji obserwujemy w przypadku kombinacji nagłówka „8 na 10 osób poleca nasze produkty” i czerwonego call-to-action. Moglibyśmy wyciągnąć wniosek, że gdybyśmy testowali same nagłówki, „8 na 10” działa lepiej niż „80%”. Jest to jednak błędny wniosek: być może tylko w kombinacji z czerwonym call-to-action ten nagłówek osiąga taki wynik. Popatrzcie na warianty z żółtym przyciskiem – wtedy to „80%” jest lepszy. Nie możemy więc zakładać, że skoro kombinacja „8 na 10” i czerwony przycisk call-to-action ma największy współczynnik konwersji, sam nagłówek również będzie miał najwyższy współczynnik w innej kombinacji.
Chcielibyśmy powiedzieć, że dajemy Ci gwarancję: jeżeli unikniesz tych 8 błędów w analityce internetowej, twoje analizy danych będą zawsze na medal. Niestety, na analityków czyha dużo więcej pułapek, o których jeszcze pewnie nie raz napiszemy.
Trzymamy kciuki za Wasze (oby poprawne, rzetelne i skuteczne) analizy.


Tagi:
Historie sukcesów
Ostatnie wpisy na blogu