W biznesie często mówi się o dobrej jakości danych. Ostatnio pod jednym z moich postów na LinkedInie zostałem zapytany, co w rzeczywistości znaczą dobre dane. Postanowiłem rozwinąć tę myśl w tym artykule.
Jakościowe dane a analityka online
Jakościowe dane a pierwsze źródło prawdy
Trafność vs dokładność danych w Google Analytics
Docelowy poziom dokładności danych
Konfiguracja narzędzi analitycznych a dokładności danych
Jakościowe dane w serwisach innych niż e-commerce
Jakościowe dane a decyzje biznesowe
Nowoczesne narzędzia i automatyzacja jakości danych w 2026
Podsumowanie
Dobra jakość danych to kluczowy element skutecznej analityki internetowej. Warto zaznaczyć, że jakość danych online można oceniać z różnych punktów widzenia. W tym wpisie przedstawię różne aspekty, które wpływają na jakość danych i jak można je lepiej wykorzystać w biznesie.
W kontekście danych, często podkreślam, że celem analityki internetowej jest podejmowanie właściwych decyzji z wykorzystaniem danych online. Właściwe decyzje są możliwe tylko wtedy, gdy dysponujemy dobrymi danymi.
Pojawia się tutaj koncepcja GIGO, czyli Garbage In, Garbage Out. Oznacza to, że wnioski z naszych analiz są tyle warte, ile dane, które do tych analiz wkładamy. Co to jednak znaczy, że dane są dobre? Jakie dane nie są śmieciowe, czyli nie są wspomnianym „garbage”? Aby odpowiedzieć na to pytanie, musimy najpierw zdefiniować, czym jest pierwsze źródło prawdy w ramach danych, którymi dysponujemy w firmie.
Warto zacząć od stwierdzenia jednego z amerykańskich prezydentów, który mówił, że w życiu pewne są tylko dwie rzeczy… Pierwsza to śmierć, a druga to podatki. Właśnie na podatkach warto się zatrzymać, aby zdefiniować, czym jest prawda w kontekście danych i biznesu.
Podatki są ściśle powiązane z Urzędem Skarbowym, który wylicza je na podstawie sprawozdań finansowych dostarczanych przez firmy. Sprawozdania finansowe są generowane na podstawie raportów księgowych, które bazują na transakcjach i zamówieniach generowanych przez nasz sklep, czyli e-commerce. Można więc powiedzieć, że pierwszym źródłem prawdy jest nasz system transakcyjny, czasami nazywany hurtownią danych, innym razem CRM (przyjmijmy, że to właśnie on jest naszym pierwszym źródłem prawdy)
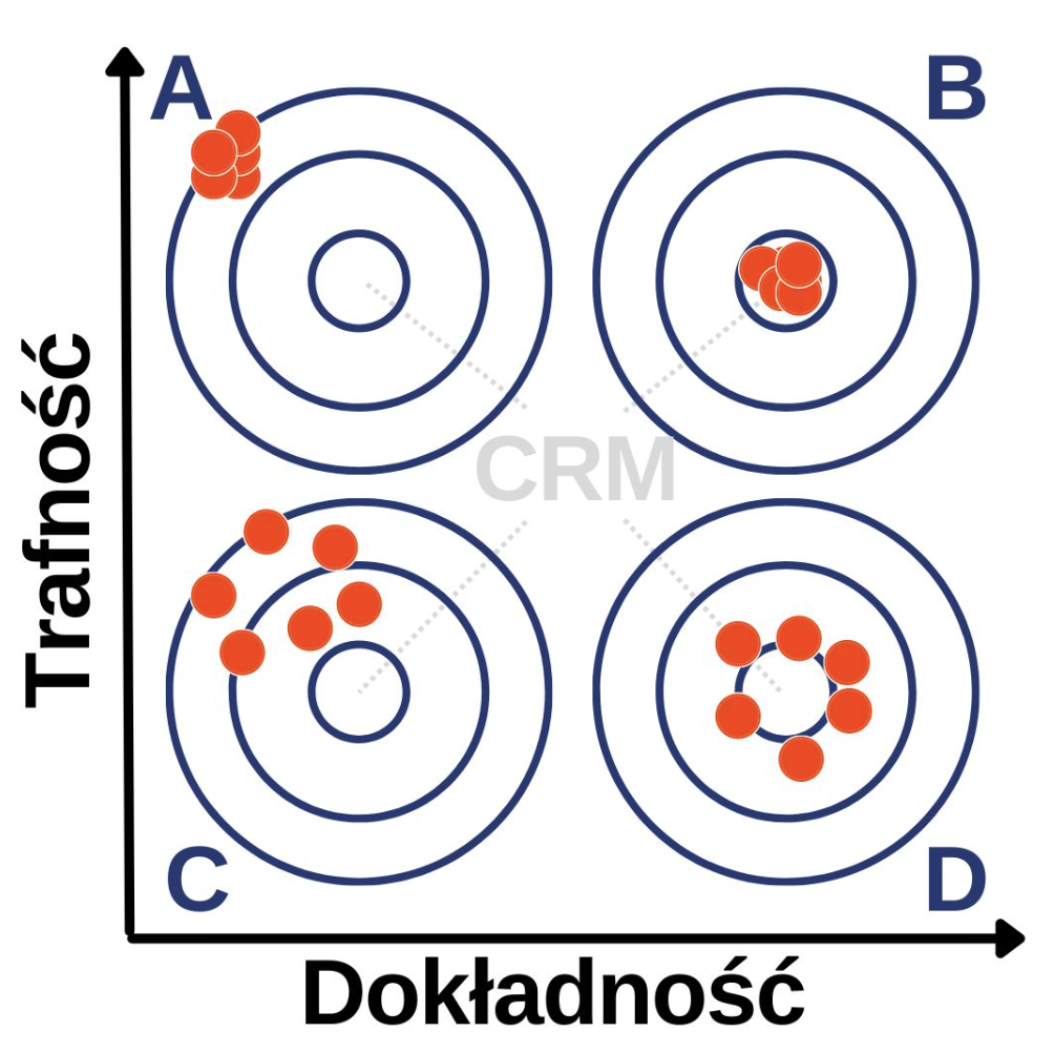
W kontekście jakości danych w analityce internetowej warto rozróżnić dwa pojęcia: trafność i dokładność danych. Dokładność oznacza, że dane są precyzyjne, czyli narzędzie analityczne pokazuje takie same wartości jak pierwsze źródło prawdy, na przykład CRM. Jeśli firma generuje 10 mln zł przychodów miesięcznie, narzędzie rejestrujące te dane powinno dokładnie pokazywać tę samą kwotę. Innymi słowy, raporty przychodów w Google Analytics 4 powinny dokładnie odzwierciedlać dane z systemu CRM. Wówczas możemy mówić, że narzędzie jest dokładne.
Drugim pojęciem określającym jakość jest trafność. Trafność oznacza, że zmiany w kształtowaniu się metryk, na przykład przychodu, są analogiczne w różnych narzędziach. Jeśli CRM pokazuje, że przychód rośnie o 10% miesięcznie, to Google Analytics również powinien pokazywać te same zmiany.
 Dokładność vs trafność danych w Google Analytics
Dokładność vs trafność danych w Google Analytics
Dokładność jest mniej realna ze względu na sposób działania narzędzi analitycznych, które opierają się na technologii, takiej jak ciasteczka czy JavaScript. Użytkownicy mogą blokować te elementy, co wpływa na dokładność danych. W analizie ważniejsza jest jednak trafność. Trendy w narzędziu analitycznym powinny być analogiczne do trendów w pierwszym źródle prawdy.
Dlaczego to jest ważne? Dane służą do podejmowania właściwych decyzji. Jeśli wysuniemy rekomendację na podstawie tych danych i postąpimy zgodnie z nią, w ramach cyklu PDCA będziemy chcieli sprawdzić, czy podjęte działania rzeczywiście mają odzwierciedlenie w danych. Jeżeli narzędzie jest trafne i pokaże, że podjęte działanie spowodowało wzrost efektywności o 15%, to ten sam wzrost powinien nastąpić w pierwszym źródle prawdy. W ekonomii istnieje zasada znana jako Ceteris Paribus, która mówi, że jeżeli pozostałe czynniki są niezmienione, to zmiana metryki w narzędziu analitycznym powinna również wystąpić w pierwszym źródle prawdy. Trafność narzędzia jest zatem kluczowa, choć oczywiście im dokładniejsze narzędzie, tym lepiej.
Jaki poziom dokładności jest odpowiedni? Przed erą Cookie Management Platform i większej świadomości dotyczącej ciasteczek, zakładaliśmy, że dokładność powinna wynosić 85%. Oznacza to, że 85% danych z pierwszego źródła prawdy powinno być widoczne również w systemie analitycznym, zwłaszcza w Google Analytics 4. W związku z Consent Mode 2 oraz różnicami we wdrożeniach, ten poziom dokładności może się jednak obniżyć. Dążymy do osiągnięcia 85% pokrycia. Jeśli nie możemy tego osiągnąć zmianami, wyjaśniamy, skąd bierze się ta luka. Może to być związane z grupą odbiorców odwiedzających nasz serwis. Są to podstawowe czynniki określające jakość.
Kolejnym aspektem jest dokładność narzędzi. Ważne jest, jak precyzyjnie zbieramy dane z punktu widzenia konfiguracji. Analizując ograniczenia narzędzi, szczególnie Google Analytics 4 w bezpłatnej wersji, warto zwrócić uwagę na kilka istotnych kwestii. Jeśli posiadamy duży serwis, w interfejsie pojawia się próbkowanie przy korzystaniu z eksploracji lub bardziej zaawansowanych analiz. Dodatkowo, eksport danych do Google BigQuery ma swoje limity. Po osiągnięciu miliona zdarzeń dziennie, kolejne zdarzenia nie są rejestrowane w BigQuery.
Dokładność danych zależy nie tylko od konfiguracji narzędzi analitycznych, ale również od ich ograniczeń. Warto być tego świadomym, aby efektywnie wykorzystywać dostępne narzędzia w marketingu online.
Jeśli nie prowadzisz e-commerce, ale zarządzasz serwisem leadowym, kontentowym lub innym, nadal możesz skutecznie korzystać z analityki online. Kluczowe jest zidentyfikowanie pierwszego źródła prawdy dotyczącego konwersji w Twoim przypadku.
Dla serwisu leadowego, gdzie generujesz potencjalnych klientów, ważne jest, abyś miał system do ich rejestrowania. Może to być skrzynka mailowa lub CRM, gdzie zapisujesz dane klientów. To właśnie to źródło będzie Twoim pierwszym punktem odniesienia, do którego porównasz dokładność i trafność narzędzia analitycznego.
W takiej sytuacji pomocny będzie wspólny klucz pomiędzy CRM a Google Analytics 4, który umożliwi precyzyjne porównanie i analizę danych. Zachęcam do przekazywania danych za pomocą timestampów. W momencie składania leada dopisuje się znacznik czasu, który jest wysyłany zarówno do CRM-a, jak i do Google Analytics 4. Na tej podstawie można sprawdzić dokładność i trafność danych.
Jeśli nie mamy konkretnej konwersji, a zaangażowanie użytkowników polega na przeglądaniu podstron, pierwszym źródłem prawdy w serwisie nie e-commerce’owym i nie lead’owym będą logi serwerowe. Logi serwerowe zawierają informacje o tym, jak różne przeglądarki, użytkownicy i klienci odpytują serwer, aby dostarczył im treść. To rejestr tego, co dzieje się na serwerze, w tym jakie podstrony są rejestrowane.
Warto pamiętać, że logi serwerowe często trzeba włączyć na poziomie serwera. Należy upewnić się, że zawierają co najmniej dwie informacje: timestamp oraz IP użytkownika. Na tej podstawie można porównywać unikalne IP użytkowników w Google Analytics 4 lub analizować odpytywania podstron, czyli zderzenia o nazwie page view (odsłony). Logi serwerowe będą naszym pierwszym źródłem prawdy.
Ostatnia kategoria to jakość danych, która ma znaczenie czysto biznesowe. Dotychczas omawiane kwestie były technologiczne, dotyczące zbierania danych i wykorzystywanych narzędzi. Czy te narzędzia mają jakieś limity? Może się okazać, że z technologicznego punktu widzenia i konfiguracji dane zbieramy prawidłowo, ale biznes przychodzi do nas z pytaniem dotyczącym konkretnego zachowania użytkownika i nagle okazuje się, że nie mamy na ten temat danych.
To również świadczy o jakości naszych danych. Ważne jest, czy dane pokrywają większość zapytań i potrzeb biznesowych. Oczywiście nie pokryjemy stu procent potrzeb, ponieważ zawsze w toku rozwoju firmy może pojawić się coś nowego, czego nie uwzględniliśmy.
Aby zadbać o jakość danych, warto przed przystąpieniem do naprawy technologicznych aspektów przeprowadzić warsztat z różnymi interesariuszami danych w organizacji. Należy zastanowić się, jakich danych i na jaki temat potrzebują. Kluczowym elementem jest warsztat biznesowy, a następnie skonfigurowanie analityki tak, aby zbierane dane i prowadzone analizy odpowiadały na pytania biznesu.
W 2026 roku jakość danych coraz częściej zależy od nowoczesnych rozwiązań technologicznych, które automatyzują jej monitorowanie i utrzymanie. Systemy klasy *data quality tools* automatycznie walidują dane, śledzą ich pochodzenie (lineage) oraz wykrywają anomalie zanim trafią do raportów, co zmniejsza ryzyko błędnych decyzji biznesowych. Automatyzacja takich procesów nie tylko przyspiesza pracę zespołów analitycznych, ale też podnosi zaufanie do danych wykorzystywanych w strategii i analizach predykcyjnych.
Co oznacza, że dane online są dobre? Przede wszystkim muszą być trafne i w miarę dokładne. Nie muszą być w stu procentach precyzyjne, ponieważ takiej dokładności nigdy nie osiągniemy. Ważne jest także, aby odpowiadały na większość pytań biznesowych. Oczywiście, nie zawsze uda się uzyskać wszystkie odpowiedzi, ponieważ biznes ciągle się rozwija i pojawiają się nowe pytania. Jednak warto dążyć do sytuacji, w której dane pokrywają 80% wszystkich pytań biznesowych, zgodnie z zasadą Pareto. To powinno być zachowane, a przeprowadzenie warsztatu biznesowego powinno przynieść oczekiwane rezultaty.


Tagi:
Historie sukcesów
Ostatnie wpisy na blogu