Co ma największy wpływ na decyzje zakupowe Twoich klientów? Czy “motywatorem” okazał się filmik wrzucony do social mediów, merytoryczny artykuł opublikowany bezpośrednio na firmowym blogu lub ciekawy newsletter? A może powodem, dla którego finalnie “skonwertowali” była dobrze zaplanowana i poprowadzona kampania PPC w wyszukiwarce Google lub Facebooku?
Jeżeli prowadzisz swoje działania za pomocą jednego nośnika informacji – sprawa wydaje się dość prosta. W końcu jedno źródło oznacza, że Twoi klienci na 99,9% pochodzą właśnie z niego. “Schody” zaczynają się wówczas, gdy swoje działania marketingowe prowadzisz na wielu frontach, a do promocji swojego biznesu angażujesz kilka lub kilkanaście źródeł. Jak wówczas poradzisz sobie z “przypisywaniem zasług” do tego, który konwertuje najlepiej?
Na szczęście masz mnie, a ja nowy wpis, w którym wyjaśnię Ci, czym jest atrybucja, jakie są jej rodzaje, a przede wszystkim – co to wszystko może oznaczać dla Twojego biznesu.
Co znajdziesz w tym artykule?
Atrybucja – co to takiego?
Jakie modele wykorzystuje się w atrybucji?
Modele atrybucji oparte o założenia. Czym są i jak działają?
Modele atrybucji oparte na danych (data-driven attribution). Co to takiego?
Jaka działa data-driven attribution?
Jakie dane może wykorzystywać atrybucja data-drive?
Czy o atrybucję data-driven możesz zadbać we własnym zakresie?
Atrybucja – podsumowanie
Jeżeli na sam dźwięk słowa “atrybucja” przypominają Ci się najgorsze sceny ze szkolnych lekcji – uspokajam. Zaraz wszystko Ci wyjaśnię 😊. Choć brzmi groźne, tajemniczo i skomplikowanie, atrybucja w marketingu to tak naprawdę cały zestaw reguł i zależności, które pozwalają określać skuteczność Twoich działań promocyjnych.
W zależności od zastosowania konkretnych modeli, atrybucja odpowiada na pytanie: co wpłynęło na ostateczną decyzję danego użytkownika?
Można więc powiedzieć, że pozwala przypisywać wartości (wagi) do konkretnych źródeł ruchu (np. działań SEO, reklam płatnych Google Ads i Facebook Ads, e-maili i newsletterów, a nawet pushy i wielu innych). W ten sposób dostarcza informacji, które z nich miało największy wpływ na finalną konwersję, a które przyczyniło się do niej w najmniejszym stopniu.
W tym miejscu warto zapamiętać, że ostateczne rezultaty, a co za tym idzie – płynące z nich wnioski, zależą od wyboru metodyki badania. Te same działania, ale mierzone innym sposobami – mogą dostarczyć zgoła odmiennych wniosków.
Dlatego, zanim wybierzesz konkretny model atrybucji, musisz wziąć pod uwagę, że każde narzędzie dostarcza innych danych. Co za tym idzie – wnioski z nich płynące mogą być zupełnie odmienne.
Doskonały przykład w tej materii stanowią różnice występujące między Google Ads i Google Analytics 4.
Pierwsze z nich “skupia się” na aktywnościach związanych z prowadzeniem płatnych kampanii reklamowych w przestrzeniach należących do Google’a (wykorzystujących do tego search, video, czy chociażby display). To naturalnie ogranicza możliwości wnioskowania i atrybucji – do tych konkretnych źródeł danych.
Z kolei Google Analytics ma dostęp do zdecydowanie większej ilości informacji. Agreguje bowiem dane z całego ekosystemu Google (w tym kampanii płatnych i działań organicznych), a dodatkowo może korzystać z informacji pochodzących spoza swojej infrastruktury (w tym: mediów społecznościowych, e-mail marketingu, web pushe i wielu innych nośników). Zatem, jak łatwo się domyślić, specyfika GA pozwala na gromadzenie większej ilości danych, a co za tym idzie – znacznie dokładniejsze i lepsze jakościowo) wnioskowanie.
Wyróżniamy dwa podstawowe podejścia do atrybucji. Pierwszy z nich opiera się o predefiniowanych założeniach (tzw. atrybucja oparta o założenia). Natomiast drugi jest związany z pracą algorytmów wykorzystujących odpowiednie dane (w tym przypadku mówimy o tzw. data-driven attribution – w skrócie DDA).
W dalszych akapitach opowiem Ci nieco więcej o obu tych podejściach, opiszę, jak działają, a dodatkowo wskażę istotne wady oraz zalety każdego z nich.
Dotychczas najbardziej popularnym podejściem do atrybucji było to odnoszące się bezpośrednio do konkretnych założeń. Mówiąc wprost – to wybór modelu w dużej mierze decydował o tym, jak będą kształtowały się wyniki potwierdzające skuteczność (lub jej brak) poszczególnych źródeł.
Pozwól, że dla lepszego objaśnienia tej kwestii, posłużę się modelami atrybucji opartej o założenia, które są dostępne w Google Analytics. Zaliczamy do nich:
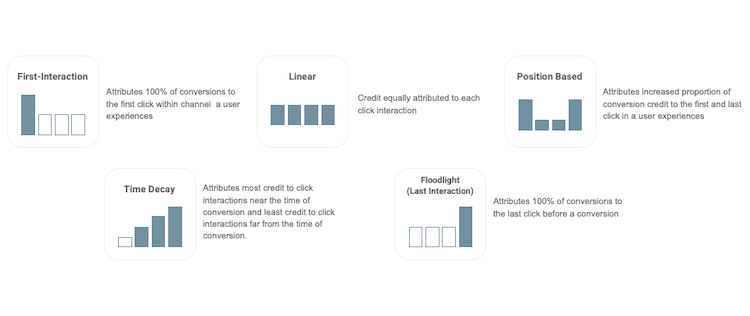 źródło: Google
źródło: Google Jak łatwo zauważyć – żaden z nich nie jest idealny. Co za tym idzie – nie da się wskazać jedynego, uniwersalnego i w pełni słusznego podejścia do mierzenia skuteczności poszczególnych źródeł ruchu.
W opozycji do atrybucji opartej o założenia stoi ta wykorzystująca dane. W tym przypadku działanie modelu nie ogranicza się do “z góry” wskazanych założeń. Zamiast tego podejście data-driven zakłada, że metodyka nie wykorzystuje stale określonych wag, a analizie poddaje się cały szereg różnych zmiennych.
W tym podejściu niezwykłe istotną rolę odgrywa dostęp do danych. Mianowicie, aby atrybucja data-driven spełniała swoe zadania, musi opierać się na odpowiedniej ilości i co najważniejsze – poprawnie zbieranych informacji.
DDA liczy więc tzw. inkrementalność poszczególnych kanałów, które pojawiły się na drodze użytkownika oraz (pośrednio lub bezpośrednio) doprowadziły do wykonania przez niego konkretnej akcji (np. zakupu).
Zbiera dane dotyczące tego, w jaki sposób użytkownicy wchodzą w interakcję z reklamami oraz innymi nośnikami informacji. Analizuje szereg zmiennych i na ich podstawie, na bieżąco decyduje o tym, jakie czynniki są brane pod uwagę do przypisywania skuteczności poszczególnych źródeł.
W ten sposób atrybucja oparta o dane pozwala mierzyć wyniki wykorzystywanych kanałów, porównywać ścieżki, obliczać prawdopodobieństwo konwersji i na podstawie osiągniętych wyników – prowadzić działania optymalizacyjne. To wszystko z kolei wpływa na ostateczne rezultaty działań promocyjnych i sprzedażowych. W dalszej kolejności warto zadbać o ciągłe testowanie, które pozwala osiągać coraz lepsze wyniki :).
W tym miejscu należy także pamiętać o pewnych ograniczeniach danych (czyli np. niepełnych ścieżkach użytkowników). Temat ten jest jednak na tyle szeroki, że szczegółowo opowiem o nim w kolejnych artykułach – tym przy okazji omawiania modeli DDA w narzędziach Google.
Model oparty na danych na bieżąco wykorzystuje zagadnienia statystyczne i matematyczne (w tym, chociażby rachunek prawdopodobieństwa). Jednak zdecydowanie najczęściej atrybucja oparta na danych korzysta z algorytmów stworzonych na bazie Łańcuchów Markowa oraz wartości Shapleya (która wywodzi się z Teorii Gier)*.
Łańcuchy Markowa odnoszą się bezpośrednio do ciągów zdarzeń, w których prawdopodobieństwo wystąpienia jednego jest zależne od wyniku poprzedniego. Z kolei przytoczona wartość Shapleya bierze pod uwagę kanały, które ze sobą współpracują i na tej podstawie sprawdza, jaki każdy z nich miał udział w ostatecznym wyniku danej kampanii.
Oczywiście, są to jedynie przykłady metodyk, które można wykorzystywać w modelowaniu atrybucji, a sam temat jest na tyle szeroki, iż z pewnością poświęcę mu niejeden, a nawet kilka artykułów.
 źródło: Google
źródło: GoogleNaturalnie, nic nie stoi na przeszkodzie, aby korzystać z możliwości, jakie oferują inne metodyki. Aczkolwiek te, o których wspomniałem, są używane zdecydowanie najczęściej.
Można więc powiedzieć, że atrybucja oparta na danych jest swego rodzaju “czarną skrzynką”, do której analitycy i inne osoby odpowiedzialne za pracę z kampaniami reklamowymi, mają ograniczony dostęp. Muszą więc polegać na intuicji, wiedzy i umiejętnościach ich autorów, czyli m.in. pracownikach Google’a czy Facebooka 😉.
* Więcej na temat tych zagadnień przeczytasz na Wikipedii.
Naturalnie, nie ma żadnych przeciwwskazań, aby “rozświetlić tę skrzynkę” i tworzyć własne narzędzia do atrybucji data-driven. Takie działanie da Ci pełny dostęp do danych oraz wpływ na to, jakie z nich są brane pod uwagę podczas analizy skuteczności działań.
Jednak uprzedzam, że takie działanie jest bardzo złożone. Wymaga posiadania odpowiedniej wiedzy, umiejętności, ogromnej świadomość z zakresu działania mediów i analityki, a przede wszystkim – dostępu do dużej ilości bardzo wartościowych danych.
Jeżeli nie dysponujesz odpowiednimi zasobami – radzę zaufać gotowym rozwiązaniom, chociażby tym, które serwuje nam Google 😊.
To by było na tyle. Temat atrybucji danych jest bardzo szeroki, dlatego w tym artykule skupiłem się na przedstawieniu jego definicji oraz nakreśleniu ogólnych zasad działania.
Jeżeli wydał Ci się ciekawy i chcesz go jeszcze bardziej zagłębić – daj znać w komentarzu. Z chęcią przygotuję dla Ciebie kolejne wpisy, w których jeszcze bardziej przybliżę Ci zagadnienie związane z atrybucją. Zarówno tą dotyczącą założeń, jak i tą związaną z danymi.


Tagi:
Historie sukcesów
Ostatnie wpisy na blogu