Spotkałeś się kiedykolwiek z sytuacją, że w Twoim Google Analytics widoczne były dane różniące się od tych, zbieranych przez inne narzędzia? Jeżeli tak, na pewno zastanawiałeś się, czy jest to normalna sytuacja i jak należy się nią przejmować. Aby odpowiedzieć sobie na te pytania, warto najpierw wiedzieć, jakiego poziomu rozbieżności w danych między narzędziami powinieneś się spodziewać – czyli takiego, który możemy uznać za standardowy czy dopuszczalny. Kluczowym krokiem będzie również określenie, do czego nasze dane porównujemy, czyli co jest dla nas pierwszym źródłem prawdy. Ale po kolei…
Pierwsze źródło prawdy – punkt odniesienia
Prezentacja danych w Google Analytics
Dane w Google Analytics a RODO
Jaki poziom rozbieżności danych jest akceptowalny?
Jak sprawdzić poziom rozbieżności danych w serwisie?
Rozbieżności w danych w zależności od typu serwisu
Google a inne systemy reklamowe
Jak ograniczyć rozbieżności w danych za pomocą zmian w rejestrowaniu transakcji
Podsumowanie
W Conversion najczęściej współpracujemy z serwisami e-commerce, w związku z czym głównym punktem odniesienia w projektach, które realizujemy jest system magazynowo-księgowy. To właśnie on najczęściej stanowi wspomniane wcześniej pierwsze źródło prawdy, względem którego porównujemy inne dane takie jak liczba transakcji czy przychody z tych transakcji.
Gdy mówimy o porównaniu danych z Google Analytics do tych z systemu wewnętrznego firmy (systemu transakcyjnego czy CRM), musimy mieć świadomość, że mówimy o dwóch obszarach porównywania danych – ich trafności oraz dokładności. Zacznijmy od wyjaśnienia tych dwóch kluczowych pojęć.
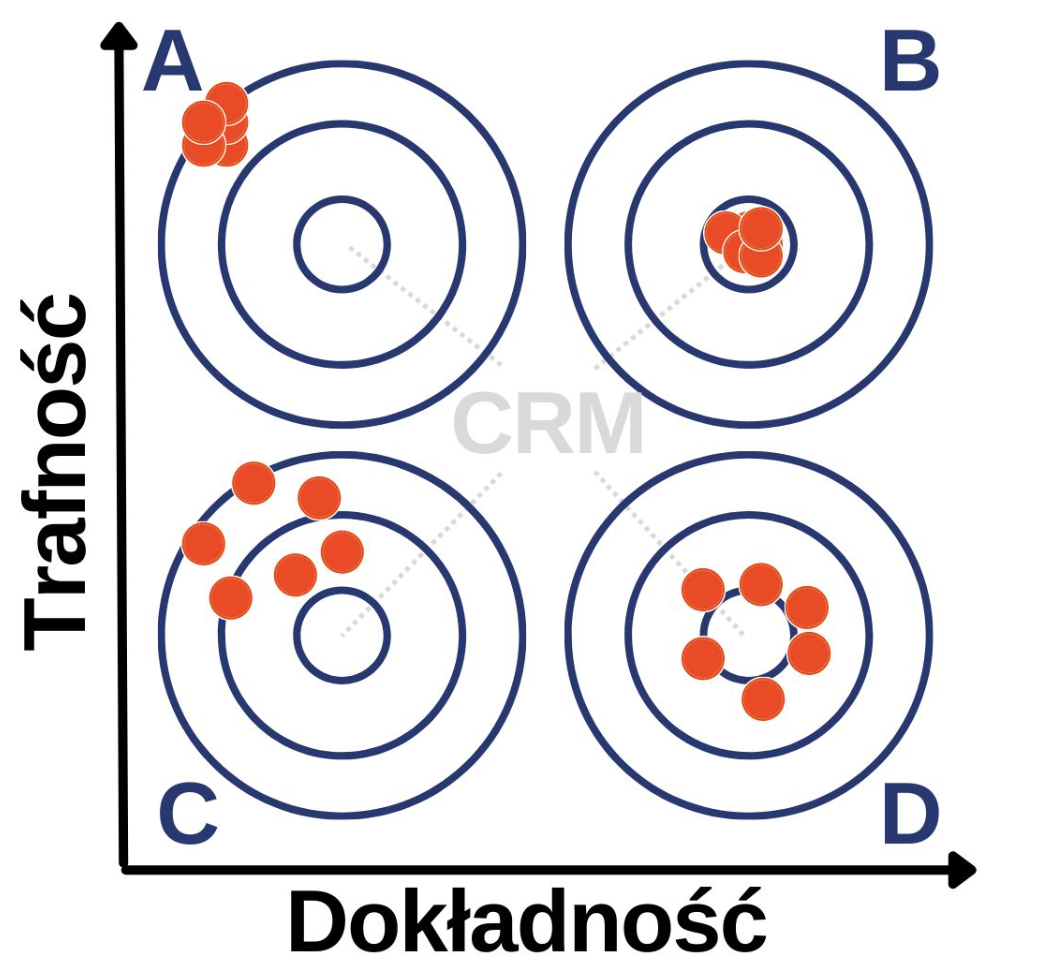
Trafność vs dokładność w Google Analytics
O trafności mówimy w momencie, gdy jakieś narzędzie zewnętrzne (tutaj Google Analytics) pokazuje dokładnie te same dane, które widzimy w naszym punkcie odniesienia. Na potrzeby tego artykułu przyjmijmy, że w przypadku ecommerc’ów jest to system CRM. Znajdziemy w nim np. dane na temat zamówień złożonych w naszym sklepie. Jeżeli Google Analytics zbiera dane cechujące się trafnością, liczba transakcji będzie równa tej w systemie wewnętrznym.
W przypadku badania dokładności zbieranych danych, nie zwracamy już uwagi na dokładne odwzorowanie danych w ujęciu ilościowym. Tutaj dużo ważniejszym elementem są trendy. Jeżeli w naszym CRM liczba transakcji rośnie w badanym okresie w danym tempie, powinno to być odzwierciedlone również w naszym Google Analytics.
Google Analytics zbiera – a co za tym idzie – prezentuje dane w oparciu o kilka fundamentów. Pierwszym z nich jest JavaScript, który jest osadzony w serwisie w kodzie źródłowym strony lub wprowadzony w nią za pomocą Google Tag Managera. Uruchamia się on w momencie załadowania strony. Jego zadaniem jest tworzenie i odczytywanie ciasteczek (cookies), które zawierają w sobie unikalne ID użytkownika. W takim wypadku mówimy, że Google Analytics operuje na podstawie JavaScriptów. Jednak nie wszyscy odwiedzający naszą stronę mają włączoną obsługę JavaScriptów czy ciasteczek. Użytkownicy często również wykorzystują wtyczki, które celowo blokują nie tylko reklamy, ale również skrypty Google Analytics. W takiej sytuacji działania wykonane przez użytkownika nie będą śledzone.
Wróćmy teraz do pojęcia dokładności. Jak wspomnieliśmy wcześniej, główną funkcją Google Analytics jako narzędzia klasy Digital Analytics nie jest jest pokazywanie dokładnie tych samych danych co system wewnętrzny. Jego głównym celem jest to, aby łączyć źródło ruchu użytkownika (miejsce, z którego trafił do serwisu) z jego zachowaniem w serwisie, gdy już do niego trafił. Dzięki temu zarządzający stroną internetową otrzymują informacje potrzebne do oceny tego, jak w zależności od źródeł ruchu i zachowań w serwisie, użytkownik realizuje pożądane przez niego akcje – czyli dokonuje konwersji. Musimy więc pamiętać, że narzędzia do analityki internetowej istnieją po to, aby odpowiadać na pytania dotyczące realizacji celów, które postawiliśmy przed naszym serwisem, a nie do zbierania w 100% dokładnych danych. To niestety nie jest możliwe ze względu na blokowanie części udostępnianych informacji przez użytkowników.
Żyjemy w czasach coraz większej dbałości o prywatność użytkowników (RODO). Od jakiegoś czasu właściciele serwisów muszą aktywnie podchodzić do uzyskiwania zgód użytkowników na tworzenie i wykorzystywanie ciasteczek. Oczywistym jest więc, że im więcej użytkowników wchodzących na nasz serwis tej zgody nie wyrazi, tym rozbieżności w danych będą większe. Z tego powodu, Google Analytics nigdy nie odzwierciedli 1 do 1 danych, które są zbierane w systemie wewnętrznym. Dlatego tak ważne jest badanie trendów, które obserwujemy w CRM i porównywanie ich z tymi notowanymi w Google Analytics 4.
Często podczas współpracy z klientami zdarza się, że gdy nie mamy odnotowanych 100% transakcji w Google Analytics, są one do niego “dosyłane” np. za pomocą measurement protocol. Nie jest to odpowiednie podejście do tematu rozbieżności w danych, z powodu przyczyny, która została wspomniana wcześniej – Analytics służy do oceny efektywności ruchu w zależności od jego źródeł czy zachowań w serwisie – nie do zbierania w pełni kompletnych danych. Jeżeli “doślemy” dane o transakcji z CRMu do Analyticsa, której on sam nie odnotował ze względu na blokady ciasteczek przez użytkownika, nie będziemy mieli informacji o powiązanym z nią źródle ruchu czy zachowaniu użytkownika w serwisie. W efekcie nie będziemy w stanie przyjrzeć się dokładniej tej transakcji i nie uzyskamy o niej wartościowych dla nas informacji.
Pamiętajmy więc przy korzystaniu z narzędzi analityki internetowej o ich głównej funkcji i nie wymagajmy od nich pełnej dokładności i trafności – taka sytuacja nie zdarza się w praktyce.
Po dotarciu do tego momentu artykułu, na pewno zastanawiasz się, jaki poziom rozbieżności nie powinien budzić Twojego niepokoju. Załóżmy, że dane które widzisz w Google Analytics cechują się dokładnością – trendy odpowiadają tym widzianym w systemie CRM. Zastanówmy się więc, jaki poziom trafności możemy uznać za odpowiedni.
W projektach, które realizujemy dążymy do poziomu zbieżności danych w Google Analytics z systemami wewnętrznymi na poziomie 85%. Oznacza to, że na 100 transakcji odnotowanych w systemie CRM (rzeczywista liczba transakcji w serwisie), średnio 85 powinno być odzwierciedlonych w danych w Google Analytics.
Na szczęście w serwisach ecommerce istnieje na to prosty sposób. W wewnętrznym systemie transakcyjnym (pierwszym źródle prawdy) mamy dane o wszystkich dokonanych w serwisie transakcjach, wraz z przypisanym do dokonujących ich użytkowników ID. Przy poprawnie skonfigurowanym Google Analytics, będziemy widzieli w nim te same transakcje, z tym samym przypisanym ID.
Należy więc najzwyczajniej w świecie wyeksportować dane z systemu wewnętrznego i porównać je z danymi dostępnymi w Google Analytics, a następnie sprawdzić, ilu ID z systemu CRM brakuje w Analyticsie.
Aby dokonać jak najbardziej wartościowego porównania, należy również zwrócić uwagę na cechy charakterystyczne użytkowników, po których możemy posegmentować dokonane transakcje widoczne w CRM a niewidocznie w Google Analytics. Dzięki temu pojawią się dodatkowe hipotezy na temat tego, z czego mogą wynikać rozbieżności między systemami – a to pierwszy krok do ich ograniczenia.
Wspomnieliśmy wcześniej, że w większości przypadków 85% zbieżności danych to poziom, do którego powinniśmy dążyć. Po większym zagłębieniu się w temat, odpowiedź nie jest jednak taka zerojedynkowa. Zadowalający nas poziom rozbieżności zależy również od typu serwisu – a dokładniej rzecz ujmując – od charakterystyki użytkowników serwisu.
Musimy zdawać sobie sprawę, że jako marketerzy cechujemy się, generalnie rzecz biorąc, wyższym poziomem świadomości w zakresie korzystania z internetu. Nie oznacza to jednak, że “zwykli” użytkownicy są pod tym kątem homogeniczni. Odzwierciedlenie tego stanu rzeczy jest widoczne również w poziomie rozbieżności w danych.
W serwisach gromadzących bardziej świadomych użytkowników, istnieje większe prawdopodobieństwo, że będą oni mieli wyłączone funkcjonalności przeglądarki, na podstawie których Google Analytics zbiera dane, takich jak JavaScripty czy ciasteczka. Mogą oni blokować również przesyłanie informacji o sobie do narzędzia za pomocą specjalnych dodatków, blokujących nie tylko reklamy, ale również śledzenie ich działań w internecie przez Google Analytics. W przypadku takich serwisów poziom zbieżności danych będzie zauważalnie niższy. Ma to miejsce głównie w przypadku specjalistycznych serwisów, zwłaszcza w branży IT, gdzie poziom zbieżności będzie “sięgał” nawet tylko 40-50%.
Z drugiej strony, w przypadku serwisów odwiedzanych przez średnio mniej świadomych użytkowników internetu, takich jak sklepy z odzieżą czy elektroniką, możemy spodziewać się poziomu zbieżności danych na wspomnianym już wcześniej poziomie 85% lub wyższym.
Rozbieżności między systemami wewnętrznymi a Google Analytics, to nie jedyne wyzwanie, z którym spotykają się analitycy. Różnice w danych będą zauważalne również pomiędzy poszczególnymi systemami reklamowymi (przypisanymi do różnych narzędzi marketingu internetowego) a Google Analytics 4. Dzieje się tak mimo tego, że narzędzia te oparte są na tej samej technologii JavaScript. Dlaczego więc tak się dzieje? Odpowiedzi powinniśmy szukać w stosowanym modelu atrybucji.
Dla przykładu weźmy pod lupę system reklamowy Facebooka, czyli Facebook Ads. Będzie on dążył do pokazania możliwie jak największej liczby konwersji dokonanych za pomocą reklam w tym systemie po to, aby przyciągać do siebie zachęconych wynikami reklamodawców. Z drugiej strony Google Analytics odbierający te dane nie ma już takiego interesu. Możemy więc założyć, że dane w Google Analytics 4 powinny być bardziej obiektywne.
Aby zobrazować tę swego rodzaju wojnę gigantów między firmami, przyjrzyjmy się reklamom w aplikacji mobilnej Facebook’a. Jak większość użytkowników, w naszych telefonach mamy zapewne zainstalowaną przeglądarkę w formie in-app, działającą na tzw. WebView. W takim przypadku, w momencie przejścia z Facebooka na serwis zewnętrzny, nie jest on wyświetlany w nowej przeglądarce, w wyniku czego dostęp do danych z perspektywy Google Analytics jest blokowany. Właśnie dlatego dane dostępne w systemie reklamowym Facebooka zauważą i odnotują tę akcję – w przeciwieństwie do Analyticsa. W wyniku takiego działania, jako reklamodawcy jesteśmy zachęcani do korzystania z danych w systemie reklamowym Mety – bo to właśnie tam zobaczymy te dane.
Podczas analizy danych musimy pamiętać o tych niuansach i wybrać najodpowiedniejszy (najbardziej rzetelny) dla nas model atrybucji, i to nim kierować się w dalszych analizach. Każdy z nich ma swoje wady i zalety, dlatego to decyzja o tym w jaki sposób chcemy analizować dane jest kluczowa – nie chcemy przecież doprowadzić do sytuacji, w której liczba konwersji pochodząca z wykorzystywanych systemów reklamowych kilkukrotnie przewyższa faktyczną liczbę transakcji widoczną w systemie CRM.
Jednym z najczęściej pojawiających się problemów w temacie rozbieżności danych w ecommerce są te związane z rejestracją transakcji. Pojawiają się one gdy korzystamy z zewnętrznych bramek płatności. W takim przypadku, transakcje domyślnie rejestrowane są po powrocie użytkownika do serwisu. Użytkownicy jednak bardzo często po dokonaniu płatności nie wracają już do serwisu, co powoduje spore rozbieżności…
Jak temu zaradzić? Rekomendujemy zliczanie transakcji w Google Analytics tuż przed samym przejściem do zewnętrznej płatności. Z naszych obserwacji wynika, że istnieje zdecydowanie większe prawdopodobieństwo tego, że użytkownik po dokonaniu płatności nie wróci do serwisu, niż to że przejdzie do jej dokonywania i zaraz po tym zrezygnuje. Dzieje się tak ze względu na dwie rzeczy:
Ze względu na powyższe, w celu zniwelowania rozbieżności w danych, rekomendujemy ustawienie zliczania konwersji tuż przed przejściem do bramki płatności.
Korzystając z narzędzi do analityki internetowej pamiętajmy, jakie jest ich przeznaczenie i nie traktujmy ich jako jedynego źródła prawdy. Dane zbierane w tego rodzaju narzędziach powinny cechować się dokładnością (a nie trafnością) i to do niej powinniśmy dążyć, a zadowalającym nas poziomem zbieżności w większości przypadków jest 85%. W zależności od typu serwisu nie zawsze będzie to jednak możliwe, i to również powinniśmy mieć na uwadze. W analizach zwracajmy większą uwagę na spójność trendów między Google Analytics a CRM, niż na trafnym odzwierciedleniu liczby transakcji. Dzięki temu świadoma analiza zaprowadzi nas do bardziej wartościowych wniosków!

Tagi:
Historie sukcesów
Ostatnie wpisy na blogu