Big Data to dzisiaj bardzo popularny termin. Internet jest niesamowicie mierzalnym medium, przez co dysponujemy morzem danych. Co to w rzeczywistości oznacza dla naszych narzędzi analitycznych–w szczególności dla Google Analytics?
Na pewno część z Was spotkała się w swojej pracy z Google Analytics z informacją o próbkowaniu danych.

Co to tak naprawdę dla nas oznacza? Czy powinniśmy się tym przejmować, czy jednak stawiać wnioski z pewną dozą ostrożności? Czy podejmując decyzje na podstawie takich danych możemy być pewni ich trafności?
W tym artykule od podstaw wytłumaczę czym jest i jak działa próbkowanie w Google Analytics? Pokaże na podstawie Google Analytics Premium, jakie przekłamanie niosą raporty próbkowania danych.
Próbkowanie w statystyce oznacza proces, w którym z populacji (np. mieszkańców kraju) losujemy jakąś reprezentację (grupę ludzi) i na jej podstawie podajemy cechy całej populacji. Dobrym przykładem są tutaj badania sondażowe partii politycznych. W sondażach bierze udział pewna część społeczeństwa (próba), która deklaruje poparcie dla danej opcji politycznej. Na tej podstawie następnie jest obliczane poparcie całego społeczeństwa.
Jest to jedyny sposób, aby w ramach ograniczonego budżetu badania opisać całą populację–trudno jest w końcu pytać każdego Polaka z czynnym prawem wyborczy, na którą partię jest skłonny w danym momencie zagłosować. Następuje tu swoista wymiana pomiędzy wartością poznawczą badania, a kosztem przeprowadzenia takiego sondażu. Trudno w końcu co miesiąc organizować mini wybory parlamentarne–badania sondażowe bazują na próbie ok 1-2 tysięcy Polaków.
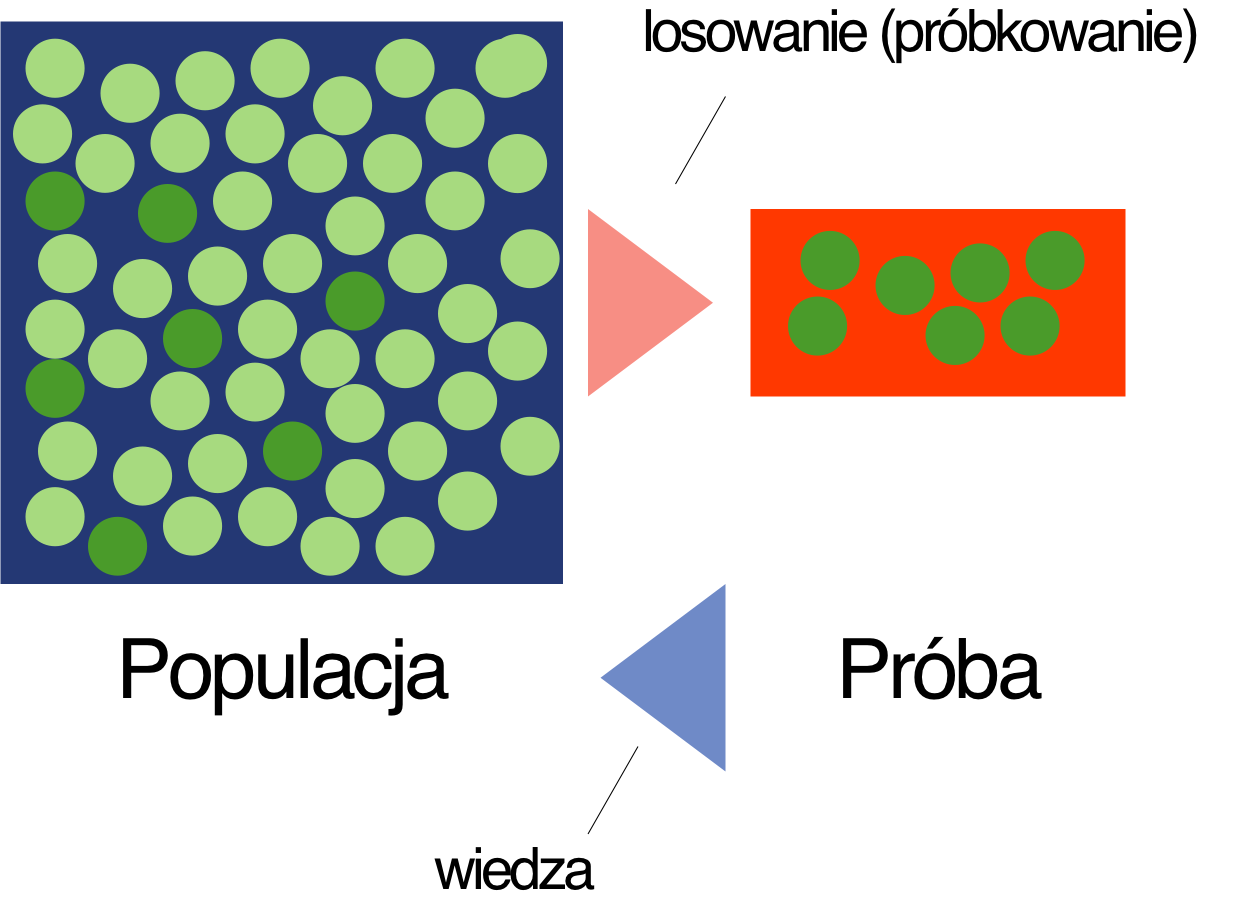
Dzięki mechanizmom losowania (losowego doboru) próby uznaje się, że metryki opisujące próbę odzwierciedlają stan całej populacji. Stąd wyniki sondażowe niemal w całkowitym stopniu pokrywają się z późniejszymi wyborami parlamentarnymi. Ich dokładność zależy tak naprawdę od doboru próby, czyli tego czy agencje badawcze prawidłowo wybiorą ludzi do badania.
Próbkowanie w Google Analytics polega na tym samym, z tym że tutaj zachodzi wymiana pomiędzy dokładnością obliczania metryk, które widzimy w raportach, a czasem ładowania raportów w interfejsie narzędzia. W przypadku dużych serwisów mamy do czynienia z ogromną ilością danych opisujących zachowanie użytkowników. Wszystkie te dane składowane są na odległych serwerach Google. Jeżeli chcemy wykonać analizę bazującą na większym zakresie danych, to Google Analytics musi wówczas odpytać bazy danych znajdujące się na tych serwerach. W związku z ogromną ich ilością nie może wziąć wszystkich pod uwagę, ale uruchamia mechanizm próbkowania, którym w tym większym stopniu działa, im większy ruch (więcej danych) generuje serwis.
Część z Was może zadać pytanie: „Ok, mam bardzo duży ruch, ale kiedy włączam wszystkie „podstawowe” raporty, to nie widzę, aby dane były próbkowane. Dopiero w momencie włączenia segmentu zaawansowanego lub dodania wymiaru dodatkowego mechanizm próbkowania daje o sobie znać.”
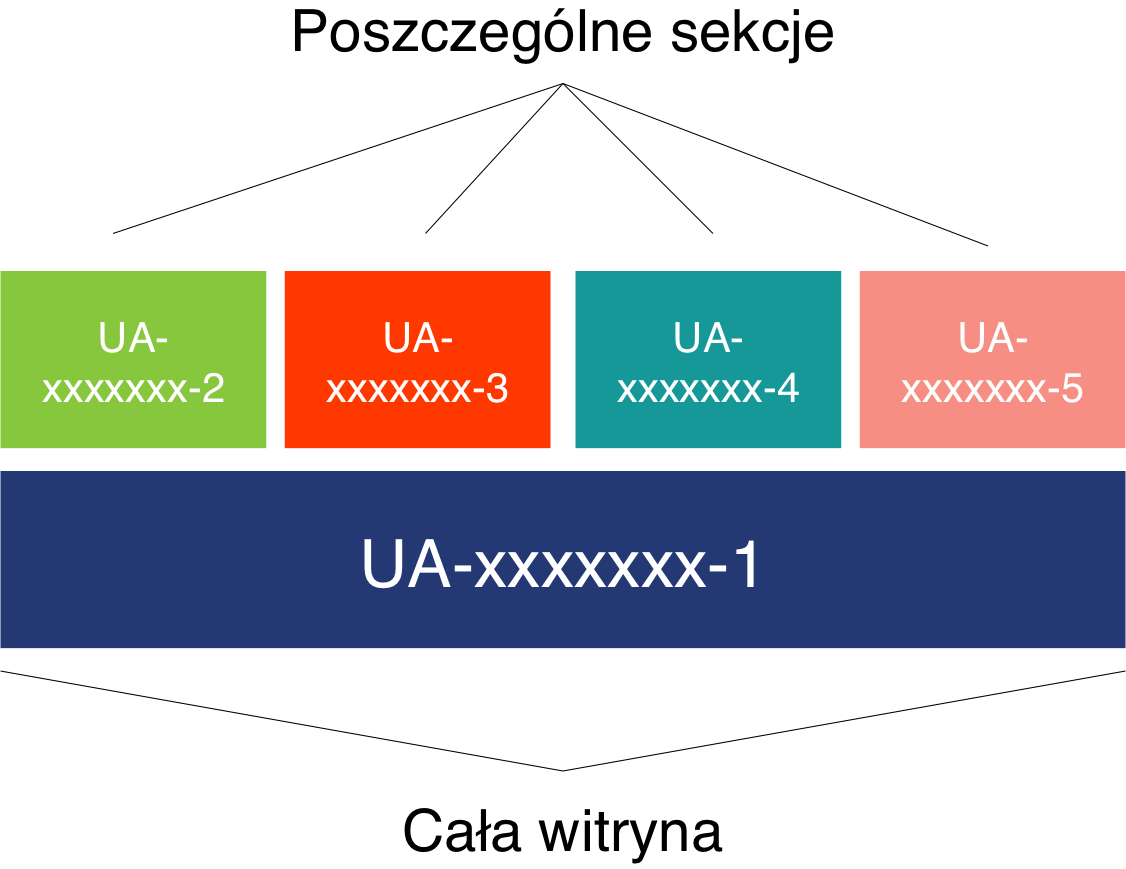
Dokładnie tak jest. Dane, które widzimy w predefiniowanych raportach są obrazem wszystkich danych leżących na serwerze. Poniżej pewnego progu (o tym w dalszej części artykułu) nie są one próbkowane. Można zobrazować to w ten sposób:
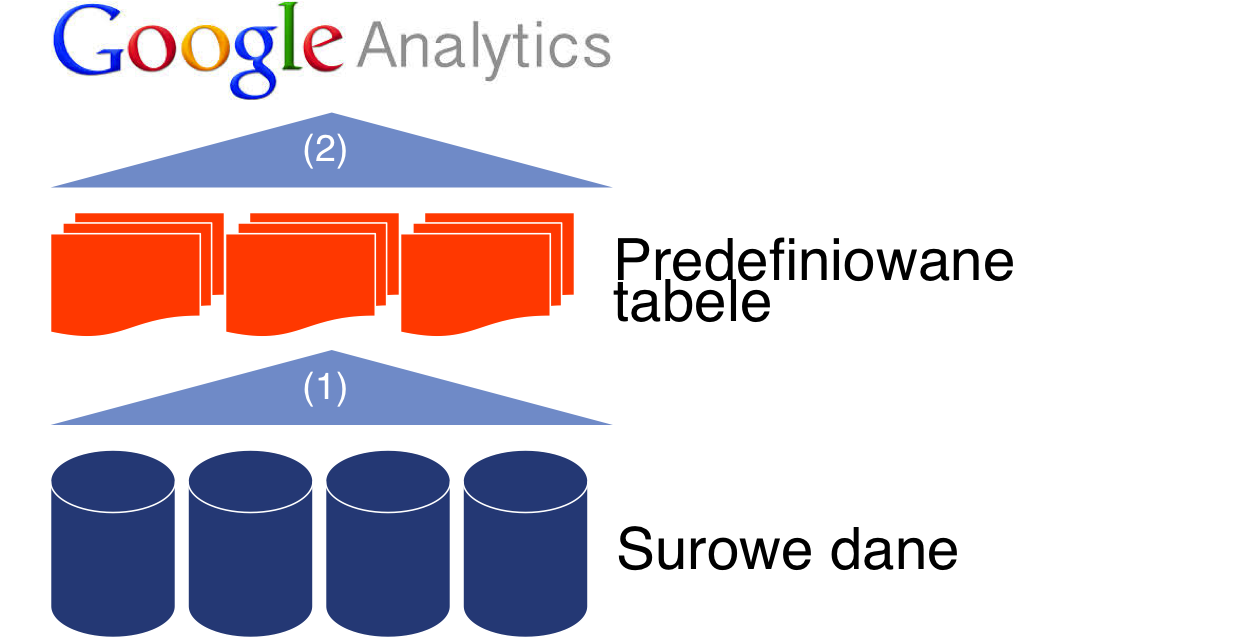
Na poziomie usługi przechowywane są surowe, cząstkowe dane dotyczące ruchu użytkowników. W każdym widoku danych tworzony jest zestaw predefiniowanych raportów, które korzystając z codziennie odświeżanych tabel, które zawierają zagregowane dane. Dzięki temu (do pewnego progu) takie raporty nie są próbkowane.
Dopiero w momencie, w którym chcemy nałożyć segment zaawansowany lub po prostu utworzyć raport niestandardowy, to interfejs musi sięgnąć do surowych danych zgromadzonych „głębiej” na serwerze i od początku je przeprocesować (omijając krok 2). Jeżeli tych danych jest tam bardzo dużo, to na poczet szybszego ładowania się docelowego raportu dane te są selekcjonowane tzn. próbkowane. To co widzimy w raporcie końcowym jest efektem obliczeń na podstawie wylosowanej próby.
Nie wszystkie raporty predefiniowane mają takie same progi, powyżej których są próbkowane. Wyjątek stanowią raporty ścieżek wielokanałowych oraz raporty przepływu. Tutaj próbkowanie następuje znacznie szybciej.
Z dużą ilością danych związane jest również zjawisko pojawiania się „(other)” w raportach. Na ten temat jednak Paweł pisał oddzielny artykuł. Przeczytacie w nim, jaki jest powód powstawania tej wartości wymiaru w raportach oraz jak sobie z nim radzić.
Oprócz tego, że raporty mogą bazować na próbkowanych danych, to takie próbkowanie możemy samodzielnie zdefiniować z poziomu kodu śledzącego. W przypadku ustawienia poziomu próbkowania np. na poziomie 50%, co drugi użytkownik brany jest pod uwagę tzn. śledzone jest jego zachowanie. Więcej na ten temat można przeczytać na stronie pomocy Google Analytics.
Metryki pokazywane w raportach Google Analytics będą poddane próbkowanie w jednym z dwóch przypadków. Każdy z nich oczywiście zależy od wolumenu ruchu, jaki generuje nasz serwis.
Próbkowanie włączy się w przypadku, którym nasz „niestandardowy” raport będzie wymagał dostępu do większej niż 1 milion unikalnych kombinacji wymiarów. Powiedzmy, że chcemy wygenerować raport, który będzie pokazywał wejścia oraz współczynnik odrzuceń dla kombinacji wymiarów: strony, przeglądarka oraz rozdzielczości ekranu. Kombinacja tych trzech wymiarów daje nam tabelę, która ma ponad 1 milion wierszy. W takim wypadku Google Analytics wyświetli nam 1 milion / liczbę dni, dla których chcemy pokazać analizę.
Jeżeli nasze „niestandardowe” zapytanie dotyczy więcej niż 500k sesji (może to łatwo nastąpić dla dłuższych okresów czasu), to wówczas dane do kalkulacji będą wzięte dla maksymalnie 500k sesji. W rzeczywistości, w momencie kiedy próbkowanie sią włącza, to mamy informację, dla jakiej liczby sesji zostały obliczone poszczególne metryki. Standardowo próbka określona jest na ok 250k sesji, ale na korzyść większej dokładności obliczeń metryk możemy wybrać wolniejszy czas ładowania się raportów.

Z założenia próba powinna odzwierciedlać całą populację, więc metryki obliczone na jej podstawie powinny być analogiczne dla całej populacji. Na pewno mniejszych przekłamań możemy spodziewać się na poziomie metryk względnych (współczynniki, średnie). Gorzej jest w przypadku metryk nominalnych, ponieważ ich wartości obliczane są po prostu jako wynik z próby pomnożony przez współczynnik próbkowania (jeżeli na podstawie próby wyjdzie, że dany wymiar miał np. 200 sesji, to przy 20% próbkowaniu dla całej populacji wartość tego wymiaru zostanie określona jako 5 x 200 = 1000 sesji).
Jak jest w rzeczywistości? Do sprawdzenia tego wykorzystaliśmy Google Analytics Premium. W wybranym raporcie „zadaliśmy pytanie” dotyczące wybranego segmentu ruchu. Otrzymaliśmy następujące wyniki:
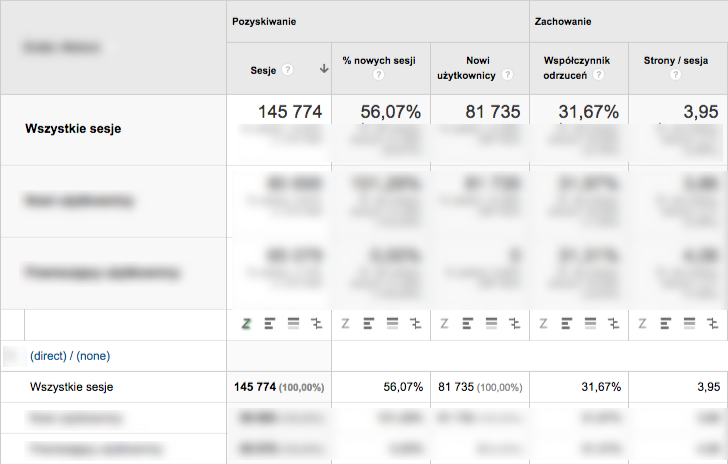
Po „zamówieniu” raportu niepróbkowanego okazało się, że metryki obliczone na podstawie wszystkich danych kształtują się następująco:

W związku z tym możemy uznać, że mechanizm próbkowania zadziałał prawidłowo. Jednak aby potwierdzić tą prawidłowość musielibyśmy powtórzyć powyższą analizę dla różnych wymiarów i metryk. Z pewnością wymiary, które normalnie są mniej reprezentowane w całej populacji mogą być niedoszacowane (trudniej jest je wylosować i na tej podstawie rzetelnie oszacować ich statystyki).
Po pierwsze, jeżeli danych Google Analytics używamy do celów kontrolingowych, to próbkowanie możemy wpłynąć na rzetelność wyników. Jeżeli raportujemy dane do systematycznych podsumowań, to w związku z próbkowaniem nasza praca może być niewłaściwie oceniona.
Również w przypadku analiz–złe dane, to w dalszej kolejności błędne wnioski i nietrafne rekomendacji, a więc błędne decyzje biznesowe. Wyzwanie w takim wypadku może okazać się poważne. Zwłaszcza, kiedy rekomendujemy działania, które wynikają z niepoprawnych danych.
Co zrobić, aby nasze analizy, a więc wnioski i rekomendacji zawsze bazowały na poprawnych (niepróbkowanych) danych?
Po pierwsze możemy przejść na Google Analytics Premium. Jeżeli generujemy na tyle duży ruch, który jest dla nas wyzwaniem przy jego analizie, to najprawdopodobniej zarabia on na nas na tyle, że powinniśmy być w stanie zainwestować w narzędzie klasy premium. Pamiętajmy, że nie jest to inwestycja bezzwrotna–analizy danych z pewnością pozwoli na poprawę naszej efektywności, a tym samym na zwiększenie przychodów/zysków z biznesu. Jestem przekonany, że inwestycja w Google Analytics Premium ma duży zwrot–warunkiem oczywiście są zasoby, które te dane są w stanie przekuć na trafne decyzje biznesowe.
Co więcej, w samym Google Analytics Premium otrzymujemy dostęp do BigQuery–systemu zarządzania bazą surowych danych Google Analytics, który umożliwia nam dostęp do bardzo granularnych danych–nawet na poziomie pojedynczych hitów. Na tej podstawie możemy tworzyć bardzo zaawansowane modele matemtyczne, które posłużą nam do prognozy przyszłej efektywności na podstawie scenariuszów zachowania naszego makrootoczenia.
Jeżeli jednak nie możemy sobie pzowlić na zakup licencji Google Analytics Premium, to również są sposoby, aby w jego bezpłatnej wersji walczyć z próbkowaniem. Poniżej podaję kilka możliwości:
Jak okazało się na podstawie przeprowadzonego eksperymentu, próbkowanie danych w Google Analytics nie przynosi duży rozbieżności pomiędzy wylosowaną próbką a stanem faktycznym. Jednak dane zostały wygenerowane na podstawie jednego segmentu.
Warto mimo wszystko swoje decyzje biznesowe podejmować na większości danych, którymi dysponujemy. Dlatego walka z próbkowaniem jest bardzo ważna. Najłatwiejsze rozwiązanie to inwestycja w narzędzie klasy premium. Jednak są również sposoby walki z próbkowaniem w bezpłatnej wersji Google Analytics. Czy macie inne, niż podane powyżej sposoby? Podzielcie się w komentarzach!

Tagi:
Historie sukcesów
Ostatnie wpisy na blogu